Возможности базы данных¶
StarRocks предлагает богатый набор возможностей для сверхбыстрой real-time аналитики на данных в больших масштабах.
MPP-фреймворк¶
StarRocks использует технологию Massively Parallel Processing (MPP). Один запрос разделяется на несколько физических вычислительных единиц, которые могут выполняться параллельно на нескольких машинах. Каждая машина имеет выделенные ресурсы CPU и памяти. MPP максимально использует ресурсы всех ядер CPU и всех машин. Производительность одиночного запроса может линейно расти по мере горизонтального масштабирования кластера.

На рисунке выше StarRocks парсит SQL‑оператор в несколько логических единиц выполнения (query fragments) в соответствии с семантикой оператора. Каждый фрагмент затем реализуется одной или несколькими физическими единицами выполнения (fragment instances) в зависимости от вычислительной сложности. Физическая единица выполнения — наименьшая планируемая единица в StarRocks. Они планируются на узлах backend (BE) для выполнения. Одна логическая единица может включать один или несколько операторов, таких как Scan, Project и Agg (см. правую часть рисунка). Каждая физическая единица обрабатывает только часть данных, а результаты агрегируются для формирования итогового набора данных. Параллельное выполнение логических единиц полностью задействует ресурсы всех ядер CPU и физических машин и ускоряет выполнение запроса.

В отличие от фреймворка Scatter‑Gather, используемого многими системами аналитики данных, MPP может задействовать больше ресурсов для обработки запросов. В Scatter‑Gather только узел Gather выполняет финальную операцию слияния. В MPP данные перераспределяются (shuffle) на несколько узлов для параллельных операций слияния. В сложных запросах, например, Group By по полям с высокой кардинальностью и объединениях больших таблиц, MPP‑фреймворк StarRocks имеет заметные преимущества над Scatter‑Gather.
Полностью векторизованный движок выполнения¶
Полностью векторизованный движок выполнения эффективнее использует вычислительную мощность CPU, поскольку организует и обрабатывает данные по столбцам. В частности, StarRocks хранит данные, организует их в памяти и вычисляет операторы SQL в колоннарном формате. Колоннарная организация максимально использует кэш CPU. Колоннарные вычисления уменьшают количество вызовов виртуальных функций и ветвлений, обеспечивая более плотный поток инструкций CPU.
Векторизованный движок также в полной мере использует SIMD‑инструкции. Этот движок выполняет больше операций над данными за меньшее число инструкций. Тесты на стандартных наборах данных показывают ускорение общей производительности операторов в 3–10 раз.
Помимо векторизации операторов, StarRocks реализует и другие оптимизации движка запросов. Например, используется технология Operation on Encoded Data для непосредственного выполнения операторов над закодированными строками без декодирования. Это существенно снижает сложность SQL и увеличивает скорость запросов более чем в 2 раза.
Разделение хранения и вычислений¶
Архитектура разделения хранения и вычислений появилась начиная с версии 3.0. В этой архитектуре вычисления и хранение разделены для изоляции ресурсов, эластичного масштабирования вычислительных узлов и высокопроизводительных запросов. Разделение хранения и вычислений обеспечивает StarRocks большую гибкость, более высокую производительность и доступность данных, а также более низкую стоимость.
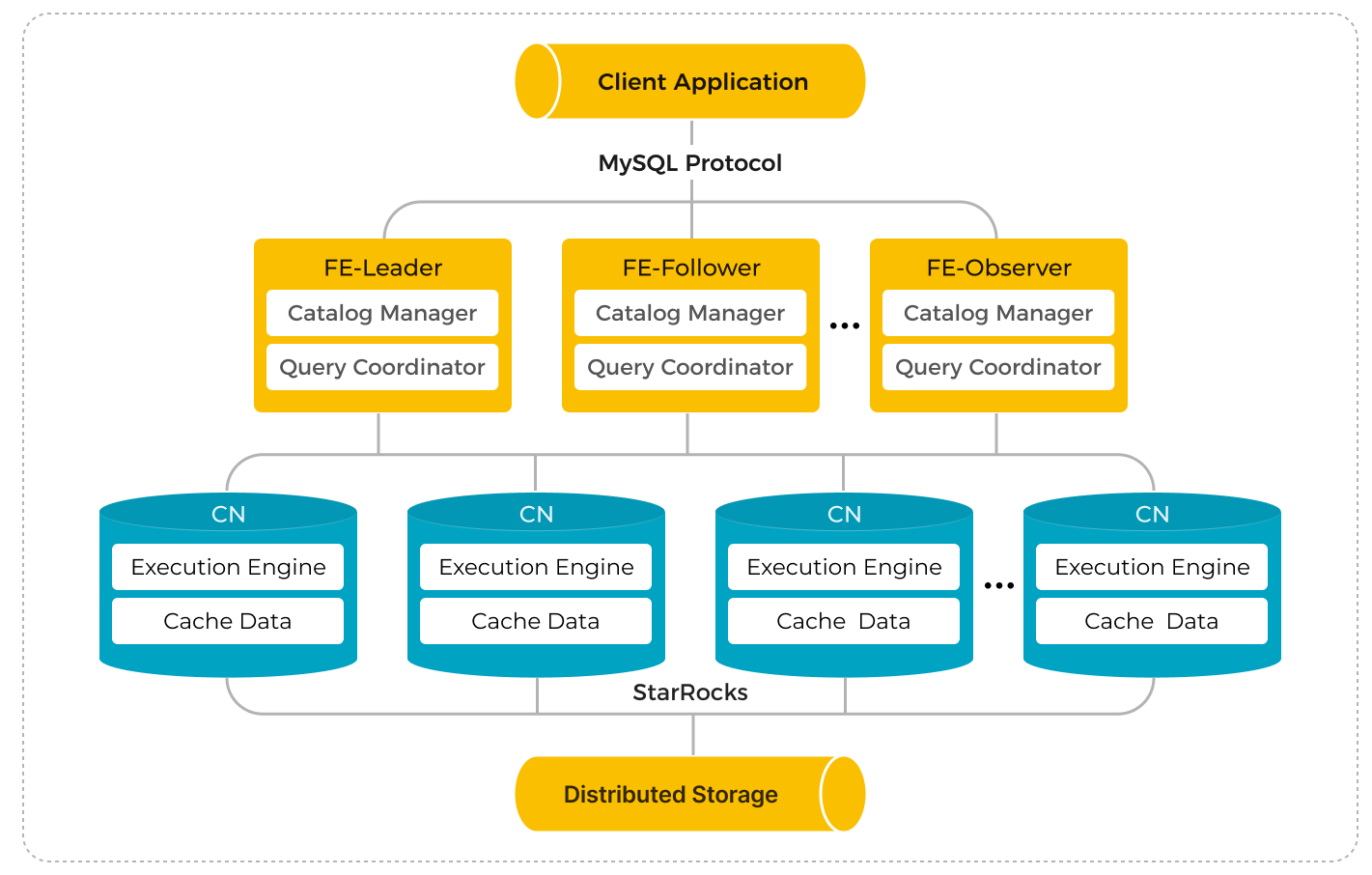
В режиме разделения хранения и вычислений они масштабируются независимо, что устраняет издержки, присущие совмещённому режиму, когда при добавлении вычислительных узлов приходилось масштабировать хранилище. Кроме того, вычислительные ресурсы можно динамически масштабировать за секунды, повышая утилизацию, особенно при выраженных пиках и провалах нагрузки.
Слой хранения использует практически неограниченную ёмкость и высокую надёжность object storage для реализации массивного хранения и целостности данных. StarRocks работает с различными системами object storage, такими как AWS S3, Google Cloud Storage, Azure Blob Storage, HDFS и другие S3‑совместимые хранилища, например MinIO.
Пользователи могут развёрнуть StarRocks в публичных облаках, частных облаках или в on‑prem дата‑центрах. StarRocks поддерживает развёртывание в кластере Kubernetes и предоставляет Operator для автоматизированного развёртывания кластеров с разделёнными хранением и вычислениями.
StarRocks в режиме разделения хранения и вычислений предоставляет те же функции, что и в совмещённом режиме. Производительность записи данных и запросов по «горячим» данным также совпадает. Пользователи могут выполнять обновления данных, аналитику по Data Lake и ускорение с помощью материализованных представлений так же, как и в совмещённом режиме.
Оптимальный план выполнения запроса с помощью Cost-based Optimizer¶

Производительность запросов с объединением множества таблиц сложно оптимизировать. Одного движка выполнения недостаточно, поскольку сложность планов может различаться на порядки в сценариях multi‑table join. Чем больше связанных таблиц, тем больше вариантов планов, и выбор оптимального становится NP‑трудной задачей. Только достаточно мощный оптимизатор запросов способен выбрать близкий к оптимальному план для эффективной многотабличной аналитики.
В StarRocks спроектирован с нуля новый оптимизатор выполнения запросов CBO (Cost_based_optimizer). Этот CBO использует каскадоподобный фреймворк и глубоко кастомизирован под векторизованный движок выполнения с рядом оптимизаций и новшеств. Среди них:
повторное использование CTE,
переписывание подзапросов,
Lateral Join,
Join Reorder,
выбор стратегий распределённого Join,
оптимизация низкой кардинальности.
CBO поддерживает суммарно 99 SQL-запросов из TPC‑DS.
CBO позволяет StarRocks обеспечивать лучшую производительность многотабличных join‑запросов по сравнению с конкурентами, особенно в сложных сценариях.
колоночное хранилище данных с real-time обновлениями¶
StarRocks — колоночное хранилище данных, в котором данные одного типа располагаются последовательно. В колоночном хранении данные можно эффективнее кодировать, повышая степень сжатия и снижая расходы на хранение. Колоночное хранение также уменьшает общий объём чтения с диска, улучшая производительность запросов. Кроме того, в большинстве OLAP‑сценариев запрашиваются только отдельные столбцы. Колоночное хранение позволяет читать только часть столбцов, значительно сокращая операции чтения-записи данных с диска.
StarRocks может загружать данные за секунды в целях real‑time аналитики и обспечивает соблюдение требований ACID для каждой операции загрузки данных. При выполнении загрузки либо весь транзакционный пакет завершается успешно, либо полностью откатывается. Параллельные транзакции не влияют друг на друга, обеспечивая изоляцию на уровне транзакций.

Движок хранения StarRocks использует шаблон Delete‑and‑insert, который обеспечивает эффективные операции Partial Update и Upsert. Движок быстро фильтрует данные с помощью primary key индекса, устраняя необходимость выполнения операций Sort и Merge при чтении. Он также эффективно использует вторичные индексы. Даже при огромных объёмах обновлений обеспечивается быстрая и предсказуемая производительность запросов.
Интеллектуальные метариализованные представления (Materialized View)¶
StarRocks использует интеллектуальные материализованные представления (MV) для ускорения запросов и различные слои хранилища данных. В отличие от других продуктов, где требуется ручная синхронизация с базовой таблицей, в StarRocks материализованные представления автоматически обновляют данные в соответствии с изменениями в базовой таблице и не требуют дополнительного обслуживания. Кроме того, выбор MV тоже автоматизирован. Если StarRocks определит подходящее MV для повышения производительности, запрос будет автоматически переписан с использованием этого MV. Такой интеллектуальный процесс значительно повышает эффективность без ручного вмешательства.
MV в StarRocks может заменить традиционное ETL‑моделирование данных: вместо преобразования данных во внешних системах вы можете выполнять трансформации с помощью MV внутри StarRocks, упрощая конвейер обработки данных.
Например, на рисунке исходные данные в Data Lake можно использовать для создания нормализованной таблицы на основе внешнего MV. Денормализованная таблица может быть создана из нормализованных таблиц с помощью асинхронных MV. Ещё одно MV может быть создано из нормализованных таблиц для поддержки высокой конкуррентности и лучшей производительности запросов.

Аналитика в Data Lake¶

Помимо эффективной аналитики локальных данных, StarRocks может работать как вычислительный движок для анализа данных, хранящихся в Data Lakes, таких как Apache Hive, Apache Iceberg, Apache Hudi и Delta Lake. Одной из ключевых возможностей StarRocks является external catalog, который действует как привязка к внешнему metastore. Это позволяет прозрачно запрашивать внешние источники данных без миграции. Таким образом, вы можете анализировать данные из разных систем, например HDFS и Amazon S3, в различных форматах файлов, таких как Parquet, ORC, CSV и др.
На рисунке выше показан сценарий аналитики по Data Lake, где StarRocks отвечает за вычисления и анализ, а Data Lake — за хранение, организацию и сопровождение данных. Data Lakes позволяют хранить данные в открытых форматах и использовать гибкие схемы для построения отчётов на основе «single source of truth» для BI, AI, ad‑hoc и отчётности. StarRocks полностью использует преимущества своего векторизованного движка и CBO, значительно повышая производительность аналитики по Data Lake.