План запроса¶
Оптимизация производительности запросов — распространённая задача в аналитических системах. Медленные запросы ухудшают пользовательский опыт и общую продуктивность кластера. В StarRocks понимание и интерпретация планов и профилей запросов — основа для диагностики и ускорения медленных запросов. Эти инструменты помогают:
Выявлять узкие места и «дорогие» операции
Замечать неоптимальные стратегии join или отсутствие индексов
Понимать, как данные фильтруются, агрегируются и перемещаются
Диагностировать и оптимизировать использование ресурсов
План запроса — это детальная «дорожная карта», которую генерирует FE StarRocks и которая описывает, как будет выполнен ваш SQL‑оператор. План разбивает запрос на последовательность операций — сканы, join, агрегации, сортировки — и определяет наиболее эффективный способ их выполнения.
StarRocks предоставляет несколько способов изучить план запроса:
Оператор EXPLAIN:
Используйте
EXPLAINдля отображения логического или физического плана выполнения запроса. Можно добавлять опции для управления выводом:EXPLAIN LOGICAL <query>: показывает упрощённый план.EXPLAIN <query>: показывает базовый физический план.EXPLAIN VERBOSE <query>: показывает физический план с подробной информацией.EXPLAIN COSTS <query>: включает оценку стоимости для каждой операции, что помогает диагностировать проблемы со статистикой.
EXPLAIN ANALYZE:
Используйте
EXPLAIN ANALYZE <query>, чтобы выполнить запрос и вывести фактический план выполнения вместе с реальными статистиками времени. См. документацию Explain Analyze для деталей.Пример:
EXPLAIN ANALYZE SELECT * FROM sales_orders WHERE amount > 1000;Query Profile:
После запуска запроса вы можете просмотреть подробный профиль выполнения, включающий времена, использование ресурсов и статистику на уровне операторов. См. документацию Query Profile о том, как получать и интерпретировать эту информацию.
SQL‑команды:
SHOW PROFILELISTиANALYZE PROFILE FOR <query_id>— получение профиля выполнения конкретного запроса.FE HTTP Service: доступ к профилям через веб‑интерфейс FE StarRocks в разделах Query или Profile, где можно искать и изучать детали выполнения.
Управляемые версии: в cloud/managed развёртываниях используйте предоставленную веб‑консоль или дашборд мониторинга для просмотра планов и профилей, часто с улучшенной визуализацией и фильтрацией.
Как правило, план запроса используют для диагностики проблем планирования и оптимизации, а профиль запроса — для выявления проблем производительности на этапе выполнения. В следующих разделах мы рассмотрим ключевые концепции выполнения запросов и разберём конкретный пример анализа плана.
Поток выполнения запроса¶
Жизненный цикл запроса в StarRocks состоит из трёх основных фаз:
Planning: запрос проходит парсинг, анализ и оптимизацию, в результате чего формируется план.
Scheduling: план распределяется планировщиком и координатором на все участвующие backend‑узлы.
Execution: план исполняется с использованием конвейерного движка выполнения (pipeline execution engine).
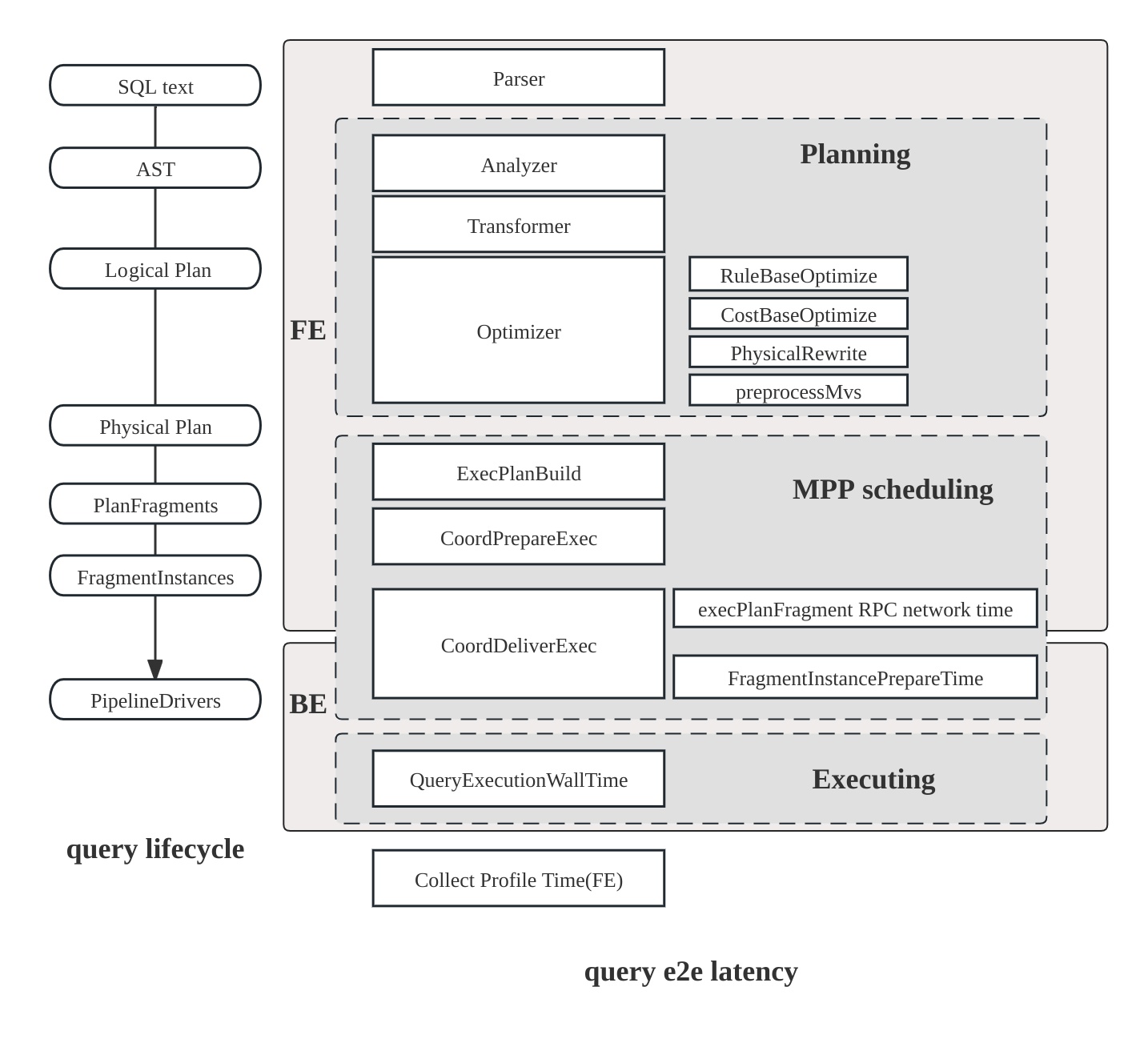
Структура плана
План StarRocks иерархический:
Fragment: верхнеуровневая единица работы; каждый фрагмент порождает несколько FragmentInstances, которые выполняются на разных backend‑узлах.
Pipeline: внутри инстанса pipeline связывает операторы; несколько PipelineDrivers исполняют один и тот же pipeline параллельно на отдельных CPU‑ядрах.
Operator: атомарный шаг — scan, join, aggregate — который обрабатывает данные.

Конвейерный движок выполнения (Pipeline)
Pipeline Engine исполняет план запроса параллельно и эффективно, обрабатывая сложные планы и большие объёмы данных для высокой производительности и масштабируемости.

Стратегия слияния метрик
По умолчанию StarRocks объединяет уровни FragmentInstance и PipelineDriver, чтобы уменьшить объём профиля, оставляя упрощённую трёхуровневую структуру:
Fragment
Pipeline
Operator
Поведение слияния можно контролировать переменной сессии pipeline_profile_level.
Пример¶
Как читать план и профиль запроса¶
Поймите структуру: планы делятся на фрагменты, каждый из которых представляет этап выполнения. Читается «снизу вверх»: сначала узлы сканирования, затем join, агрегации и, наконец, выдача результата.
Общий анализ:
Проверьте общее время, использование памяти и отношение CPU/wall time.
Найдите медленные операторы, отсортировав по времени оператора.
Убедитесь, что фильтры максимально проталкиваются вниз (pushdown).
Ищите перекос данных (неравномерные времена операторов или число строк).
Следите за высоким использованием памяти или spill на диск; при необходимости скорректируйте порядок join или используйте rollup/MV.
Используйте materialized view и query hints (
BROADCAST,SHUFFLE,COLOCATE) для оптимизации при необходимости.
Операции сканирования: ищите
OlapScanNodeи подобные. Отметьте, какие таблицы сканируются, какие фильтры применены и используются ли предагрегация или materialized view.Операции соединения (Join): определите типы join (
HASH JOIN,BROADCAST,SHUFFLE,COLOCATE,BUCKET SHUFFLE). Метод join влияет на производительность:Broadcast: маленькая таблица рассылается на все узлы; подходит для малых таблиц.
Shuffle: строки перераспределяются и перемешиваются; подходит для больших таблиц.
Colocate: таблицы партиционированы одинаковым образом; позволяет локальные join.
Bucket Shuffle: перемешивается только одна таблица — снижает сетевые издержки.
Агрегация и сортировка: ищите
AGGREGATE,TOP-NилиORDER BY. Эти операции дороги на больших/высококардинальных данных.Перемещение данных: узлы
EXCHANGEпоказывают передачу данных между фрагментами или узлами. Избыточное движение данных вредит производительности.Predicate pushdown: раннее применение фильтров (на уровне скана) уменьшает последующие объёмы данных. Проверьте
PREDICATESилиPushdownPredicates, чтобы увидеть, какие фильтры протолкнуты вниз.
Пример плана запроса¶
Это запрос 96 из бенчмарка TPC‑DS.
explain logical
select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
Вывод — это иерархический план, показывающий, как StarRocks выполнит запрос. План организован как дерево операторов, которое читается снизу вверх. Логический план показывает последовательность операций с оценками стоимости:
- Output => [69:count]
- TOP-100(FINAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669801.20}
- TOP-100(PARTIAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669769.20}
- AGGREGATE(GLOBAL) []
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 0.00, cost: 68669737.20}
69:count := count(69:count)
- EXCHANGE(GATHER)
Estimates: {row: 1, cpu: 8.00, memory: 0.00, network: 8.00, cost: 68669717.20}
- AGGREGATE(LOCAL) []
Estimates: {row: 1, cpu: 3141.35, memory: 0.80, network: 0.00, cost: 68669701.20}
69:count := count()
- HASH/INNER JOIN [9:ss_store_sk = 40:s_store_sk] => [71:auto_fill_col]
Estimates: {row: 3490, cpu: 111184.52, memory: 8.80, network: 0.00, cost: 68668128.93}
71:auto_fill_col := 1
- HASH/INNER JOIN [7:ss_hdemo_sk = 25:hd_demo_sk] => [9:ss_store_sk]
Estimates: {row: 19940, cpu: 1841177.20, memory: 2880.00, network: 0.00, cost: 68612474.92}
- HASH/INNER JOIN [4:ss_sold_time_sk = 30:t_time_sk] => [7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 199876, cpu: 69221191.15, memory: 7077.97, network: 0.00, cost: 67671726.32}
- SCAN [store_sales] => [4:ss_sold_time_sk, 7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 5501341, cpu: 66016092.00, memory: 0.00, network: 0.00, cost: 33008046.00}
partitionRatio: 1/1, tabletRatio: 192/192
predicate: 7:ss_hdemo_sk IS NOT NULL
- EXCHANGE(BROADCAST)
Estimates: {row: 1769, cpu: 7077.97, memory: 7077.97, network: 7077.97, cost: 38928.81}
- SCAN [time_dim] => [30:t_time_sk]
Estimates: {row: 1769, cpu: 21233.90, memory: 0.00, network: 0.00, cost: 10616.95}
partitionRatio: 1/1, tabletRatio: 5/5
predicate: 33:t_hour = 8 AND 34:t_minute >= 30
- EXCHANGE(BROADCAST)
Estimates: {row: 720, cpu: 2880.00, memory: 2880.00, network: 2880.00, cost: 14400.00}
- SCAN [household_demographics] => [25:hd_demo_sk]
Estimates: {row: 720, cpu: 5760.00, memory: 0.00, network: 0.00, cost: 2880.00}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 28:hd_dep_count = 5
- EXCHANGE(BROADCAST)
Estimates: {row: 2, cpu: 8.80, memory: 8.80, network: 8.80, cost: 44.15}
- SCAN [store] => [40:s_store_sk]
Estimates: {row: 2, cpu: 17.90, memory: 0.00, network: 0.00, cost: 8.95}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 45:s_store_name = 'ese'
Читаем план снизу вверх
План запроса следует читать от нижнего уровня (листовые узлы) к верхнему (корень), по потоку данных:
Операции сканирования (нижний уровень): операторы
SCANвнизу читают данные из базовых таблиц:SCAN [store_sales]читает основную факт‑таблицу с предикатомss_hdemo_sk IS NOT NULLSCAN [time_dim]читает таблицу измерения времени с предикатамиt_hour = 8 AND t_minute >= 30SCAN [household_demographics]читает таблицу демографии с предикатомhd_dep_count = 5SCAN [store]читает таблицу магазинов с предикатомs_store_name = 'ese'
Каждая операция сканирования показывает:
Estimates: оценка числа строк, CPU, памяти, сети и стоимости
Отношения партиций и таблетов: сколько партиций/таблетов сканируется (например,
partitionRatio: 1/1, tabletRatio: 192/192)Predicates: условия запроса, протолкнутые на уровень скана, уменьшают объём чтения
Передача данных (Broadcast): операции
EXCHANGE(BROADCAST)разносят меньшие таблицы измерений на все узлы, обрабатывающие большую факт‑таблицу. Это эффективно, когда измерения малы по сравнению с фактом, как в примере сtime_dim,household_demographicsиstore.Операции соединения (средний уровень): данные проходят вверх через
HASH/INNER JOIN:Сначала
store_salesсоединяется сtime_dimпоss_sold_time_sk = t_time_skЗатем результат соединяется с
household_demographicsпоss_hdemo_sk = hd_demo_skНаконец, результат соединяется с
storeпоss_store_sk = s_store_sk
Каждый join показывает условие соединения и оценки по числу строк и ресурсам.
Агрегация (верхний уровень):
AGGREGATE(LOCAL)выполняет локальную агрегацию на каждом узле, вычисляяcount()EXCHANGE(GATHER)собирает результаты со всех узловAGGREGATE(GLOBAL)объединяет локальные результаты в итоговый счётчик
Финальные операции (самый верх):
TOP-100(PARTIAL)иTOP-100(FINAL)реализуютORDER BY count(*) LIMIT 100, выбирая топ‑100 результатов после сортировки
Логический план содержит оценки стоимости для каждой операции, помогая понять, где запрос расходует больше всего ресурсов. Физический план (из EXPLAIN или EXPLAIN VERBOSE) включает дополнительные детали о распределении операций по узлам и параллельном выполнении.