Кластеризация таблиц¶
Грамотно выбранный sort‑key — самый эффективный рычаг физического дизайна в StarRocks. В этом руководстве объясняется, как sort key работает «под капотом», какие системные преимущества он даёт и приводится практическая методика выбора эффективного ключа под вашу нагрузку.
Пример¶
Предположим, у вас есть телеметрическая система, получающая миллиарды строк в день, каждая с device_id и ts (timestamp). Определение ORDER BY (device_id, ts) для факт‑таблицы обеспечивает:
Point‑запросы по
device_idс задержкой в миллисекундах.Дашборды, фильтрующие недавние окна времени для каждого устройства, отсекают большую часть данных.
Агрегации вроде
GROUP BY device_idвыигрывают от streaming aggregation.Сжатие улучшается за счёт серий близких временных меток на устройство.
Этот простой двухколоночный sort key ORDER BY (device_id, ts) приводит к сокращению I/O, экономии CPU и более стабильной производительности запросов на миллиардах строк.
CREATE TABLE telemetry (
device_id VARCHAR,
ts DATETIME,
value DOUBLE
)
ENGINE=OLAP
PRIMARY KEY(device_id, ts)
PARTITION BY date_trunc('day', ts)
DISTRIBUTED BY HASH(device_id) BUCKETS 16
ORDER BY (device_id, ts);
Преимущества подробно¶
Массовое исключение I/O — Segment и Page Pruning
Как это работает:
Каждый segment и 64 KB page хранят min/max для всех столбцов. Если предикат выходит за этот диапазон, StarRocks пропускает целый блок и не обращается к диску.
Пример:
SELECT count(*) FROM events WHERE tenant_id = 42 AND ts BETWEEN '2025-05-01' AND '2025-05-07';При
ORDER BY (tenant_id, ts)рассматриваются только те сегменты, у которых первый ключ равен 42, и внутри них — только страницы, чьё окно ts пересекается с указанными семью днями. Таблица на 100 B строк может просканировать менее 1 B строк, превращая минуты в секунды.Миллисекундные точечные выборки — Sparse Prefix Index
Как это работает:
Разреженный prefix‑индекс хранит примерно каждое ~1 000‑е значение sort‑key. Двоичный поиск попадает на нужную страницу, затем одно чтение с диска (часто из кэша) возвращает строку.
Пример:
SELECT * FROM orders WHERE order_id = 982347234;С
ORDER BY (order_id)зонд требует ≈ 50 сравнений ключей по таблице на 50 B строк — задержка <10 мс даже при «холодном» кэше данных.Быстрее отсортированная агрегация
Как это работает:
Когда sort key согласован с GROUP BY, StarRocks выполняет streaming aggregation на лету — без сортировки и без hash‑таблицы.
Такой план сканирует строки в порядке sort‑key и формирует группы на лету, используя локальность кэша CPU и избегая промежуточной материализации.
Пример:
SELECT device_id, COUNT(*) FROM telemetry WHERE ts BETWEEN '2025-01-01' AND '2025-01-31' GROUP BY device_id;Если таблица
ORDER BY (device_id, ts), движок группирует строки по мере поступления — без построения hash‑таблицы и пересортировки. Для высококардинальных ключей вроде device_id это может резко снизить использование CPU и памяти.Streaming aggregation на отсортированном вводе обычно даёт прирост пропускной способности в 2–3× по сравнению с hash‑агрегацией при больших кардинальностях групп.
Лучшее сжатие и «горячие» кэши
Как это работает:
Отсортированные данные образуют малые дельты или длинные серии, ускоряя dictionary, RLE и frame‑of‑reference кодеки. Компактные страницы последовательно проходят через кэши CPU.
Пример:
Телеметрическая таблица, отсортированная по (device_id, ts), показала 1.8× лучшее сжатие (LZ4) и на 25% меньшую нагрузку CPU/scan, чем те же данные без сортировки на входе.
Как работает sort key¶
Влияние sort key начинается в момент записи строки и сохраняется на каждом этапе чтения. В этом разделе — сквозной путь: write path ➜ иерархия хранения ➜ внутренности сегмента ➜ read path — чтобы показать, как каждый слой усиливает ценность упорядочивания.
Write Path
Ingest: строки попадают в MemTable, сортируются по объявленному sort key и сбрасываются как новый Rowset с одним или несколькими упорядоченными Segment.
Compaction: фоновые cumulative/base‑джобы объединяют мелкие Rowset в крупные, возвращая удалённые строки и уменьшая число сегментов без пересортировки, поскольку исходные Rowset уже имеют одинаковый порядок.
Replication: каждый Tablet (шард, владеющий Rowset) синхронно реплицируется на peer BE‑узлы, гарантируя единый порядок на всех репликах.

Иерархия хранения
Объект
Что это
Почему важно для sort key
Partition
Крупнозернистый логический срез таблицы (например, дата или tenant_id).
Включает планировочное partition pruning и изолирует операции жизненного цикла (TTL, bulk load).
Tablet
Hash/Random бакет внутри партиции, независимо реплицируемый по BE.
Единица, чьи строки физически упорядочены по sort key; вся внутрипартиционная обрезка начинается здесь.
MemTable
In‑memory буфер записи (~96 MB), сортирует по ключу до сброса на диск.
Гарантирует, что каждый on‑disk Segment уже упорядочен — внешняя сортировка позже не нужна.
Rowset
Неизменяемый набор из одного или нескольких Segment, созданный flush/stream‑загрузкой/компакцией.
Append‑only дизайн позволяет параллельную загрузку при lock‑free чтении.
Segment
Самодостаточный колоночный файл (~512 MB) внутри Rowset с data pages и pruning‑индексами.
Zone‑map и prefix‑индексы на уровне сегмента опираются на порядок, заданный в MemTable.
Внутри файла Segment
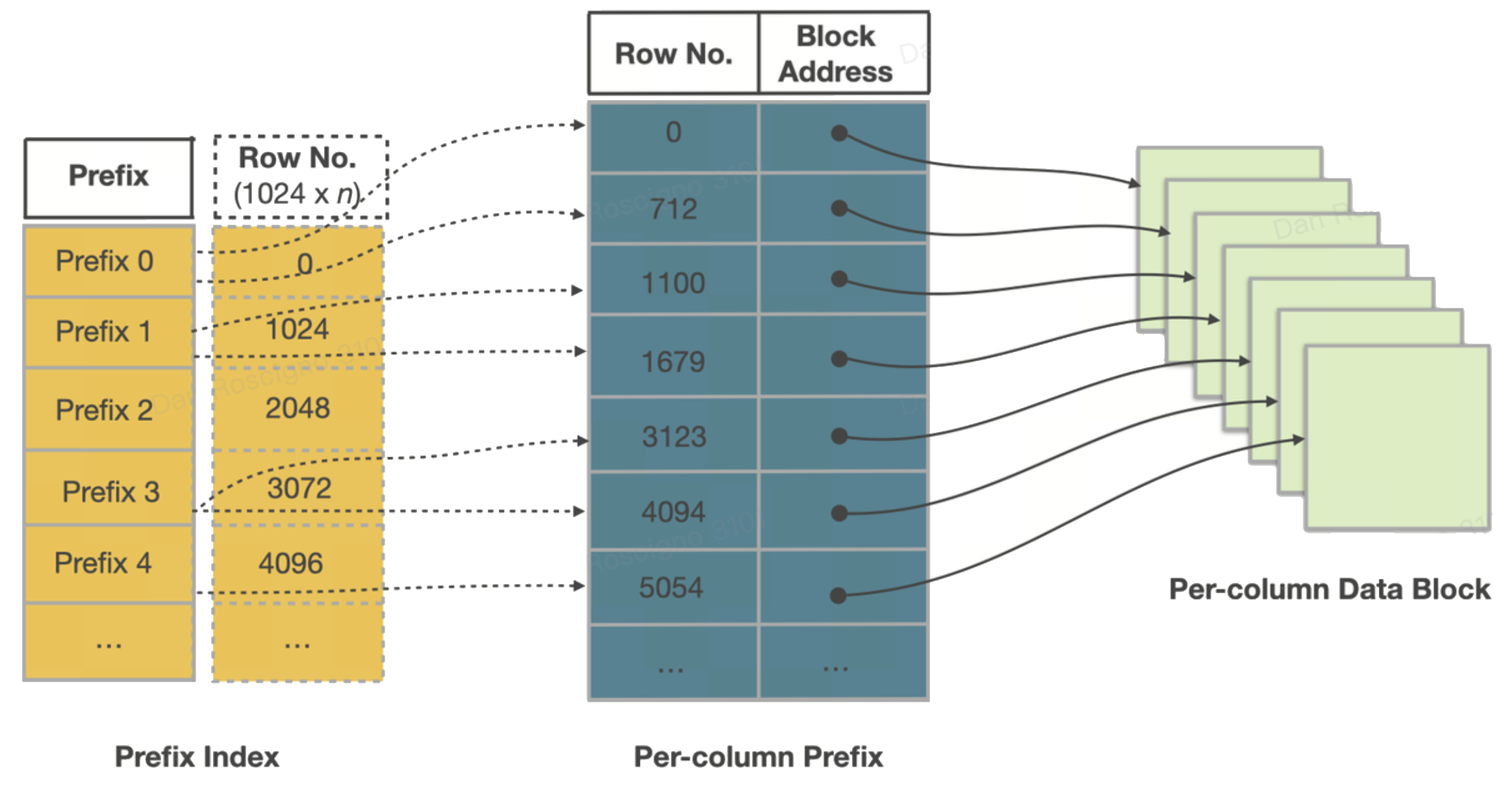
Каждый Segment самодокументирован. Сверху вниз вы найдёте:
Колоночные data pages — блоки по 64 KB, кодирование (Dictionary, RLE, Delta) и сжатие (по умолчанию LZ4).
Ordinal index — сопоставляет порядковый номер строки → смещение страницы для прямых переходов.
Zone‑map index — min, max и has_null на страницу и на весь Segment — первая линия защиты при обрезке.
Short‑key (prefix) index — разреженная таблица двоичного поиска первых 36 байт sort key примерно на каждые ~1 K строк — обеспечивает миллисекундные точечные/диапазонные выборки.
Footer и magic number — смещения индексов и контрольная сумма; позволяет StarRocks memory‑map только «хвост», чтобы обнаружить остальное.
Поскольку страницы уже отсортированы по ключу, эти индексы крошечные, но крайне эффективные.
Read Path
Partition pruning (на этапе планирования): если WHERE ограничивает ключ партиции (например,
dt BETWEEN '2025‑05‑01' AND '2025‑05‑07'), оптимизатор открывает только соответствующие каталоги партиций.Tablet pruning (на этапе планирования): когда фильтр равенства включает столбец хеш‑распределения, StarRocks вычисляет целевые tablet ID и планирует только их.
Prefix‑index seek: разреженный short‑key индекс по ведущим столбцам sort key находит точный сегмент или страницу.
Zone‑map pruning: метаданные min/max на Segment и 64 KB page отбрасывают блоки, не попадающие в окно предиката.
Векторизованное сканирование и поздняя материализация: выжившие колоночные страницы идут последовательно через кэши CPU; материализуются только затронутые строки и столбцы, что держит память под контролем.
Поскольку данные фиксируются в порядке ключа при каждом flush, каждый слой обрезки при чтении наращивает эффект предыдущего, обеспечивая субсекундные сканы на мультимиллиардных таблицах.
Как выбрать эффективный sort key¶
Начните с анализа нагрузки
Проанализируйте top‑N шаблонов запросов:
Предикаты равенства (
=/IN). Столбцы, почти всегда фильтруемые по равенству, — идеальные кандидаты в начало ключа.Диапазонные предикаты. Метки времени и числовые диапазоны обычно следуют за столбцами равенства в sort key.
Ключи агрегаций. Если диапазонный столбец также присутствует в
GROUP BY, более раннее размещение (после селективных фильтров) может включить отсортированную агрегацию.Ключи join/group‑by. Рассмотрите раннее размещение, если они распространены.
Измерьте кардинальность столбцов: высококардинальные (миллионы значений) дают лучшую обрезку.
Эвристики и практические правила
Порядок: (высокоселективные столбцы равенства) → (основной диапазонный столбец) → (помощники кластеризации).
Порядок по кардинальности: размещение низкокардинальных столбцов перед высококардинальными может улучшить сжатие.
Ширина: ограничьте 3–5 столбцами. Очень широкие ключи замедляют загрузку и выходят за 36‑байтовый лимит prefix‑индекса.
Строковые столбцы: длинный ведущий строковый столбец может занять весь 36‑байтовый префикс, что помешает эффективной индексации следующих столбцов ключа.
Это снижает силу обрезки prefix‑индекса и ухудшает точечные выборки.
Согласуйте с другими настройками дизайна
Партиционирование: выбирайте ключ партиции грубее ведущего столбца sort key (например,
PARTITION BY date,ORDER BY (tenant_id, ts)). Тогда сначала удаляются целые диапазоны дат, а внутри них работает обрезка по сортировке.Бакетирование: использование одних и тех же столбцов для бакетирования и кластеризации служит разным целям. Бакетирование обеспечивает равномерное распределение данных по кластеру, сортировка — эффективное исключение I/O.
Тип таблицы: для таблиц Primary Key по умолчанию используется первичный ключ как sort key, но можно указывать дополнительные столбцы для уточнения физического порядка и усиления обрезки. Для Aggregate и Duplicate таблиц следуйте стратегиям, ориентированным на аналитические предикаты, описанным выше.
Шаблоны‑подсказки
Сценарий
Партиция
Sort Key
Обоснование
B2C Orders
date_trunc(„day“, order_ts)
(user_id, order_ts)
Большинство запросов сначала фильтруют по пользователю, затем по недавнему периоду.
IoT Telemetry
date_trunc(„day“, ts)
(device_id, ts)
Доминируют чтения по временным рядам в разрезе устройства.
SaaS Multi‑Tenant
tenant_id
(dt, event_id)
Изоляция по арендаторам через партицию; сортировка кластеризует по дням для дашбордов.
Dimension Lookup
none
(dim_id)
Небольшая таблица, чистые точечные выборки — достаточно одного столбца.
Заключение¶
Хорошо спроектированный sort key меняет небольшой и предсказуемый overhead загрузки на драматическое снижение латентности сканирования, повышение эффективности хранения и утилизации CPU. Ориентируясь на реальные шаблоны нагрузки, уважая кардинальность и проверяя через EXPLAIN, вы сохраните высокую производительность StarRocks даже при росте данных и пользователей на порядок и более.